







Harness the power of
with precision and control
AI powers your most impactful applications. WhyLabs gives you the tools to ensure these applications are secure, reliable, and performant.
Thousands of users love and trust WhyLabs:













Observe, Secure, and Optimize
your AI applications
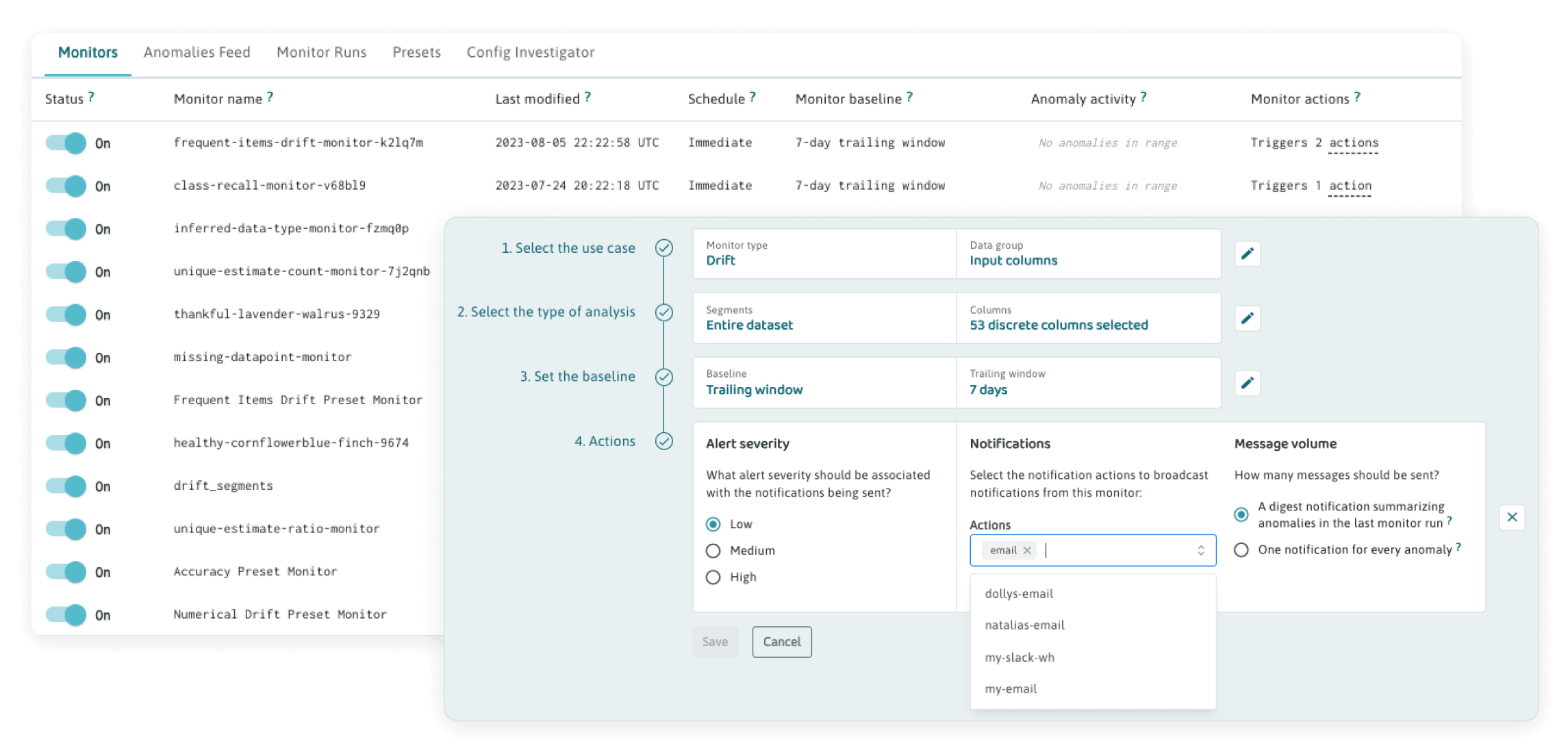
 Control every aspect of your AI application health
Control every aspect of your AI application health- Observe, flag, and block security risks in real-time
- Get notified about drift and performance degradations across all predictive models
- Automate remediation of security threats, model performance degradation, and data quality issues
- Enable seamless collaboration across ML teams, SRE teams, and security teams
- The only SaaS privacy-preserving deployment approved for highly regulated industries (Healthcare and FSI)

Large Language Models
Monitor, evaluate, and guardrail across multiple dimensions of security and quality. Safeguard proprietary LLM APIs and self-hosted LLMs.

Generative AI
Go beyond text-to-text. Secure and observe any modality - images, documents voice, or video.

Predictive AI
Enable MLOps best practices for traditional AI models with observability and monitoring for any model type.






The leader in LLMOps and MLSecOps tools











Take Control Of Your AI Applications
Best-in-class teams rely on WhyLabs to control their AI applications
 Join the responsible
Join the responsible AI Builders
Loading...
installs
Make guardrails decisions with
300
ms
avg. latency
Protect your AI experiences with
93%
avg. accuracy



Secure and Protect




Observe Any Application at Scale




Optimize and Customize




Integrate Seamlessly




Protect Privacy

What leading AI teams are saying about WhyLabs

-b772aa1070c8d1a3ba26c5992e0d3dca.svg)
“We chose WhyLabs for several reasons. First, they provide all the core model monitoring functionalities that we're looking for including a straightforward presentation of results, outlier detection, histograms, data drift monitoring, and missing feature values. [Second,] they have strong data privacy due to their aggregation of data before consumption and very fast ingestion.”
ML Platform Program Manager
Fortune 500 Fintech

“At Airspace, we use AI to minimize risk across the supply chain for the world's most critical shipments. WhyLabs has been instrumental in driving the scalability of our AI operations. The platform offers easy onboarding, data privacy-friendly integration, and a command-center view that allows us to quickly identify and treat problems before they impact the user experience. The downstream impact of enabling observability is that we are able to continuously expand on our differentiating technology by leveraging machine learning for more use cases”
Ryan Rusnak
Co-founder and CTO, Airspace










