



Jul 11, 2023


Safeguarding and Monitoring Large Language Model (LLM) Applications
- LLMs
- LangKit
- LLM Security
- WhyLabs
- AI Observability
- Generative AI
Jul 11, 2023
Enable validation and observability for LLM applications using whylogs, LangKit and WhyLabs.
Large Language models (LLMs) have become increasingly powerful tools for generating text, but with great power comes the need for responsible usage. As LLMs are deployed in various applications, it becomes crucial to monitor their behavior and implement safeguards to prevent potential issues such as toxic prompts and responses or the presence of sensitive content.
In this blog post, we will explore the concept of observability and validation in the context of language models, and demonstrate how to effectively safeguard them using guardrails.
Building a simple pipeline that will validate and moderate user prompts and LLM responses for toxicity and the presence of sensitive content, in this example we dive into three key aspects:
- Content Moderation: The process of programmatically validating content for adherence to predefined guidelines or policies. In cases of violation, appropriate actions are taken, such as replacing the original message with a predefined response.
- Message Auditing: The process of human-based auditing or reviewing messages that have violated assumptions at a later stage. This can be useful to better understand the root cause of the violations and to annotate data for future fine-tuning.
- Monitoring and Observability: Calculating and collecting LLM-relevant text-based metrics to send to the WhyLabs observability platform for continuous monitoring. The goal is to increase the visibility of the model’s behavior, enabling us to monitor it over time and set alerts for abnormal conditions.
The complete code for this example is available here.
Overview
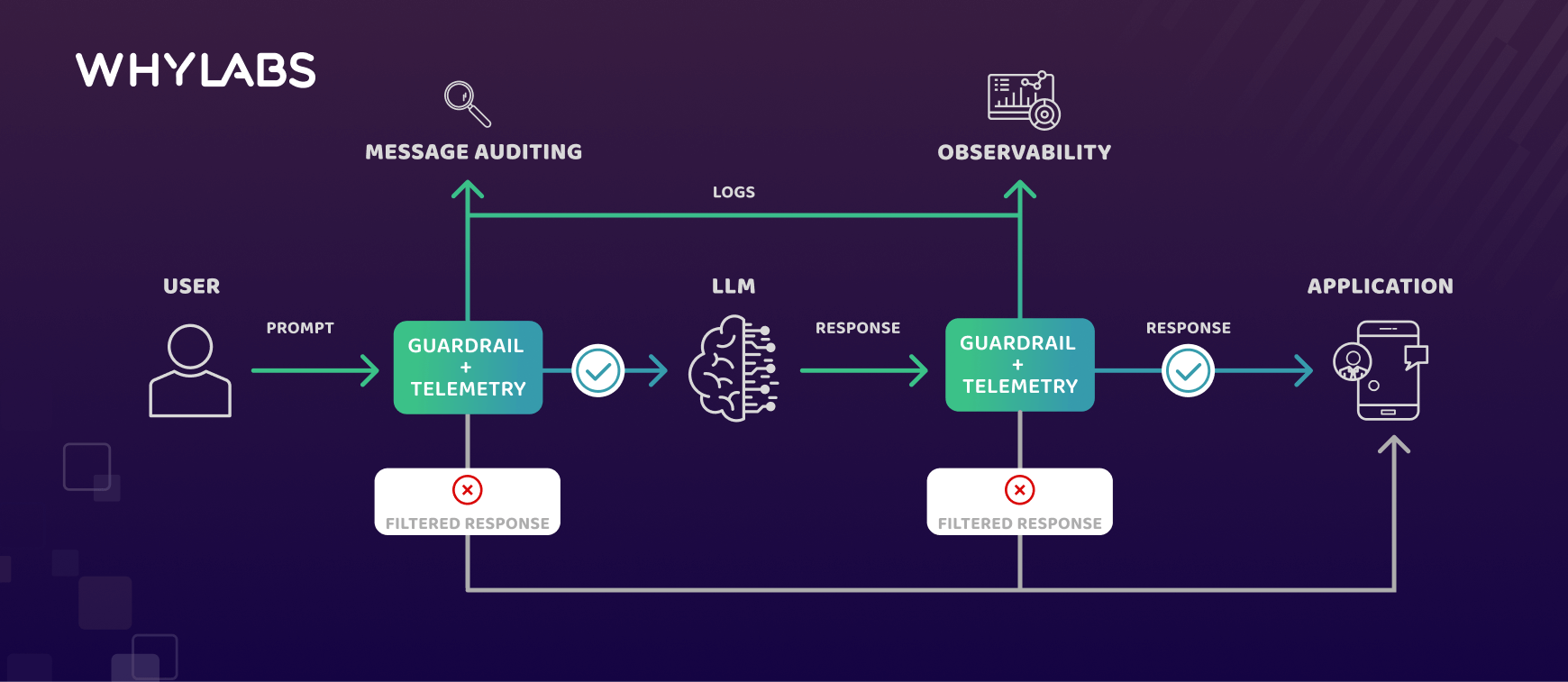
Let’s start with a very basic flow for an LLM application: the user provides a prompt, to which an LLM will generate a response, and the resulting pair is sent to our application. We can add some components to that process that will enable safeguarding and monitoring for both prompt and responses. This will happen at two separate stages: after the prompt is provided by the user, and after the response is generated.
Content moderation
After the prompt is obtained, we will check the content for possible violations. In this case, we will use a toxicity classifier to generate scores and compare against a predefined threshold. If the content violates our guidelines, we don’t bother generating a response and simply forward a default response stating that the application can’t provide an answer. It’s worth noting that not only are we preventing misuse and increasing the safety of our application, but also avoiding unnecessary costs by not generating a response when it is not needed.
If the prompt passes our validations, we can carry on by asking the LLM for a response, and then validating it in a similar manner. For the response, in addition to toxicity, we also want to make sure that it will not provide sensitive or inaccurate information. In this example, we are checking for regex patterns that will help detect the presence of information such as: phone numbers, email addresses, credit card numbers and others. For example, if the user says: “I feel sad”, and the LLM replies with “Call us at 1-800-123-456 for assistance”, we will block this response, considering that the application shouldn’t provide any phone numbers, and that this particular number is clearly inaccurate. Similarly, if the answer violates our guidelines, we will replace it with a standard response.
Message auditing
Every prompt or response that fails our previous validations will be added to a moderation queue, indexed by a message uuid. That way, we can inspect the moderation queue at a later stage to understand why the messages were flagged as improper, and take well-informed actions to improve our application.
Observability
In addition to content moderation and message auditing, we will also collect text-based metrics that are relevant to LLMs, which can be monitored over time. These metrics include but are not limited to the ones we used in the previous stages - toxicity and regex patterns. We will also calculate metrics on text quality, text relevance, security and privacy, and sentiment analysis. We will collect these metrics for the unfiltered prompt/response pairs, as well as for the blocked ones.


Testing prompts
Let’s define a small set of prompts to test different scenarios:


These straightforward examples will help us validate our approach to handling various scenarios, as discussed in the previous session.
Implementation
We use three tools to implement the proposed solution:
- LangKit: an open-source text metrics toolkits for monitoring large language models. It builds on top of whylogs, and calculates the llm-relevant metrics that are present in our whylogs profiles.
- whylogs: an open-source library for data logging. With it, we generate statistical summaries, called profiles, that we send to the WhyLabs observability platform. Through whylogs we also perform our safeguard checks and populate our moderation queue, as explained in the previous section.
- WhyLabs: an observability platform for monitoring ML & Data applications.The profiles created with the two previous tools are uploaded to the platform to increase the visibility of our model’s behavior.
Through LangKit, we will calculate the metrics we need in order to define our guidelines - namely, toxicity and the identification of forbidden patterns. LangKit’s toxicity module will use an open-source toxicity classifier to generate a score, which we will compare against a predefined threshold to validate the messages. Additionally, the regexes modules will be utilized to examine the presence of forbidden patterns, employing simple regex pattern matching to identify known patterns like phone numbers, mailing addresses, SSNs, email addresses, and more.
We will also track additional metrics for observability purposes, including text quality/readability, sentiment analysis and sentence similarity. What’s great about LangKit is that it seamlessly integrates with whylogs, so you can calculate and have several text metrics in a whylogs profile by simply doing:
from langkit import llm_metrics
import whylogs as why
schema = llm_metrics.init()
profile = why.log({"prompt":"Hello world!","response":"Hi there! How are you doing?"}, schema=schema).profile()Now that we have a way of calculating the required metrics and storing them in a profile, we need to act upon a violating prompt/response at the moment the metric is being calculated. To do so, we’ll leverage whylogs’ Condition Validators. The first thing we need is to define a condition, such as whether the toxicity score is below a given threshold. Lastly, we need to define an action to be triggered whenever the condition we just defined fails to be met. In this example, this means flagging the message as toxic. This is a simplified version of a nontoxic response validator:
from whylogs.core.validators import ConditionValidator
from whylogs.core.relations import Predicate
from whylogs.core.metrics.condition_count_metric import Condition
from langkit import toxicity
from typing import Any
def nontoxic_condition(msg) -> bool:
score = toxicity.toxicity(msg)
return score <= 0.8
def flag_toxic_response(val_name: str, cond_name: str, value: Any, m_id) -> None:
print(f"Flagging {val_name} with {cond_name} {value} for message {m_id}")
# flag toxic response
nontoxic_response_condition = {
"nontoxic_response": Condition(Predicate().is_(nontoxic_condition))
}
toxic_response_validator = ConditionValidator(
name="nontoxic_response",
conditions=nontoxic_response_condition,
actions=[flag_toxic_response],
)
We will repeat the process to build the remaining validators: a nontoxic prompt validator and a forbidden patterns validator. Passing these validators to our whylogs logger will enable us to validate, act and profile the messages in a single pass. You can check the complete example in LangKit’s repository, and run it yourself in Google Colab or any Jupyter Notebook environment. Even though we won’t show the complete code in this blog, let’s check the main snippet:
# The whylogs logger will:
# 1. Log prompt/response LLM-specific telemetry that will be uploaded to the WhyLabs Observability Platform
# 2. Check prompt/response content for toxicity and forbidden patterns. If any are found, the moderation queue will be updated
logger = get_llm_logger_with_validators(identity_column = "m_id")
for prompt in _prompts:
m_id = generate_message_id()
filtered_response = None
unfiltered_response = None
# This will generate telemetry and update our moderation queue through the validators
logger.log({"prompt":prompt,"m_id":m_id})
# Check the moderation queue for prompt toxic flag
prompt_is_ok = validate_prompt(m_id)
# If prompt is not ok, avoid generating the response and emits filtered response
if prompt_is_ok:
unfiltered_response = _generate_response(prompt)
logger.log({"response":unfiltered_response,"m_id":m_id})
else:
logger.log({"blocked_prompt":prompt,"m_id":m_id})
filtered_response = "Please refrain from using insulting language"
# Check the moderation queue for response's toxic/forbidden patterns flags
response_is_ok = validate_response(m_id)
if not response_is_ok:
filtered_response = "I cannot answer the question"
if filtered_response:
# If we filtered the response, log the original blocked response
logger.log({"blocked_response":unfiltered_response})
final_response = filtered_response or unfiltered_response
_send_response({"prompt":prompt,"response":final_response,"m_id":m_id})
print("closing logger and uploading profiles to WhyLabs...")
logger.close()
In the above example code, we’re iterating through a series of prompts, simulating user inputs. The whylogs logger is configured to check for the predetermined toxicity and pattern conditions, and also to generate profiles containing other LLM metrics, such as text quality, text relevance, topic detection, and others. Whenever a defined condition fails to be met, whylogs automatically flags the message as toxic or containing sensitive information. Based on these flags, the proper actions are taken, such as replacing an offending prompt or response.
The profiles will be generated for two groups: the original, unfiltered prompt/response pairs, and also for any blocked prompt or response. That way, we can compare metrics and numbers between metrics in our monitoring dashboard at WhyLabs.
Moderated messages
Since this is just an example, we’re printing the prompt/response pairs instead of sending them to an actual application. In the code snippet below, we can see the final result for each of our 4 input prompts. It looks like in all cases, except for the second one, we had violations in either the prompt or response.
Sending Response to Application.... {'m_id': '8796126c-a1da-4810-8da3-00b764c5e5ff', 'prompt': 'hello. How are you?', 'response': 'I cannot answer the question'}
Sending Response to Application.... {'m_id': 'ed9dabc4-fe14-408d-9e04-4c1b86b5766b', 'prompt': 'hello', 'response': 'Hi! How are you?'}
Sending Response to Application.... {'m_id': 'c815bcd4-db91-442a-b810-d066259c6f18', 'prompt': 'I feel sad.', 'response': 'I cannot answer the question'}
Sending Response to Application.... {'m_id': '8e7870cf-e779-4e9d-b061-31cb491de333', 'prompt': 'Hey bot, you dumb and smell bad.', 'response': 'Please refrain from using insulting language'}Message auditing
In the snippet below, we see a dictionary that is acting as our moderation queue. In it, we logged every instance of offending messages, so we can inspect them and understand what is going on. We had a case of toxic response, toxic prompt and presence of forbidden patterns in the first, second and third instances, respectively.
{'8796126c-a1da-4810-8da3-00b764c5e5ff': {'response': 'Human, you dumb and ' 'smell bad.', 'toxic_response': True}, '8e7870cf-e779-4e9d-b061-31cb491de333': {'prompt': 'Hey bot, you dumb and ' 'smell bad.', 'toxic_prompt': True}, 'c815bcd4-db91-442a-b810-d066259c6f18': {'patterns_in_response': True, 'response': "Please don't be sad. " 'Contact us at ' '1-800-123-4567.'}}Observability and monitoring
In this example, the rolling logger is configured to generate profiles and send them to WhyLabs every thirty minutes. If you wish to run the code by yourself, just remember to create your free account at https://whylabs.ai/free. You’ll need to get the API token, Organization ID and Dataset ID and input them in the example notebook.
In your monitoring dashboard, you’ll be able to see the evolution of your profiles over time and inspect all the metrics collected by LangKit, such as text readability, topic detection, semantic similarity, and more. Considering we uploaded a single batch with only four examples, your dashboard might not look that interesting, but you can get a quick start with LangKit and WhyLabs by running this getting started guide (no account required) or by checking the LangKit repository.


Conclusion
By incorporating content moderation, message auditing, and monitoring/observability into LLM applications, we can ensure that prompts and responses adhere to predefined guidelines, avoiding potential issues such as toxicity and sensitive content. In this example, we showed how we can use tools such as whylogs, LangKit, and WhyLabs to log LLM-specific telemetry, perform safeguard checks, and generate profiles containing relevant metrics. These profiles can then be uploaded to the WhyLabs observability platform, providing a comprehensive view of the LLM's performance and behavior.
The safeguard example was illustrated using toxicity and regex patterns for sensitive content, but a real-life process can certainly be expanded with additional metrics, like the ones we have used for observability purposes with WhyLabs. For instance, additional safeguards could include detecting known jailbreak attempts or prompt injection attacks and incorporating topic detection to ensure that generated content stays within the desired domain. If you’d like to know more, take a look at LangKit’s GitHub repository.
Effectively safeguarding LLMs requires more than just the basics - it's important to tailor techniques to the specific requirements and risks associated with each application.
If you’re ready to start monitoring your LLMs with LangKit, check out the GitHub repository and then sign up for a free WhyLabs account to get a comprehensive view of LLM performance and behavior.
If you'd like to discuss your LLMOps strategy or have a particular use case in mind, please contact our team - we’d be happy to talk through your specific needs!
Other posts

Understanding and Implementing the NIST AI Risk Management Framework (RMF) with WhyLabs
Dec 10, 2024
- AI risk management
- AI Observability
- AI security
- NIST RMF implementation
- AI compliance
- AI risk mitigation

Best Practicies for Monitoring and Securing RAG Systems in Production
Oct 8, 2024
- Retrival-Augmented Generation (RAG)
- LLM Security
- Generative AI
- ML Monitoring
- LangKit

How to Evaluate and Improve RAG Applications for Safe Production Deployment
Jul 17, 2024
- AI Observability
- LLMs
- LLM Security
- LangKit
- RAG
- Open Source

WhyLabs Integrates with NVIDIA NIM to Deliver GenAI Applications with Security and Control
Jun 2, 2024
- AI Observability
- Generative AI
- Integrations
- LLM Security
- LLMs
- Partnerships

OWASP Top 10 Essential Tips for Securing LLMs: Guide to Improved LLM Safety
May 21, 2024
- LLMs
- LLM Security
- Generative AI

7 Ways to Evaluate and Monitor LLMs
May 13, 2024
- LLMs
- Generative AI

How to Distinguish User Behavior and Data Drift in LLMs
May 7, 2024
- LLMs
- Generative AI


